Question
As shown in the post , the header data structure consists of three merkle patricia (MP for short) tree roots and some other components. Many bitcoin-like blockchains only include single one tree, i.e., the transaction tree. How come Ethereum needs as many as three trees? What would happen if we deleted one of them? Or, essentially, what’s the purpose of the existence of the three trees: the state tree, the transaction tree, and especially, the receipt tree?
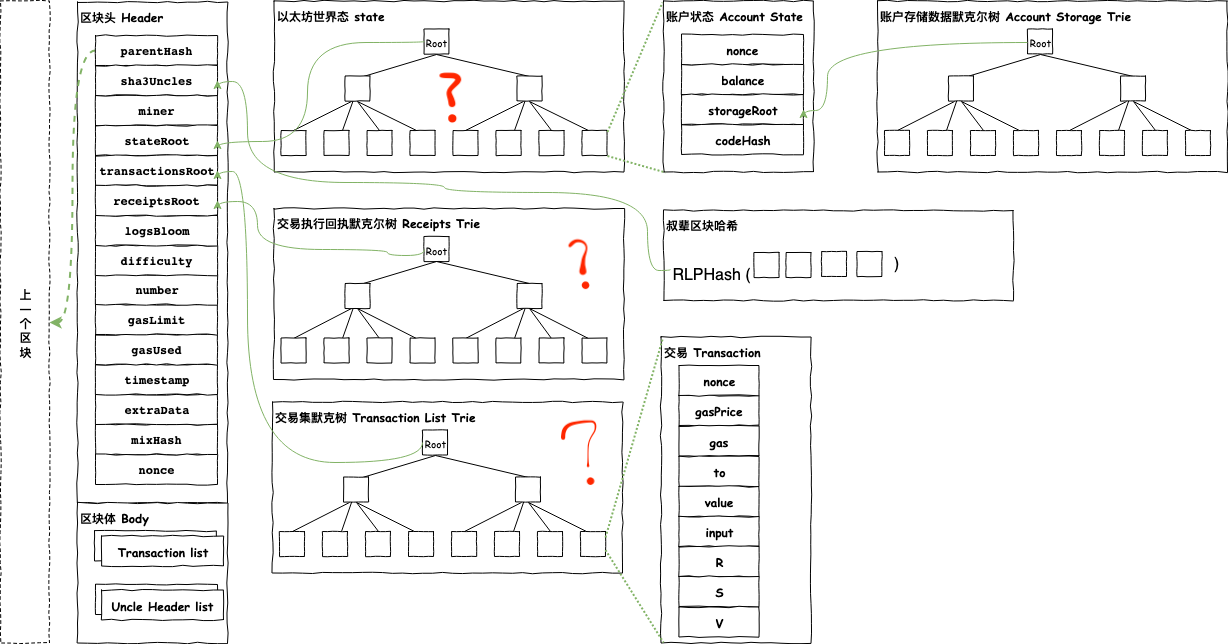
This is an open question that promoted by our chief.
The question is mainly about the receipt tree. The receipt tree is populated with the receipts of each transaction in the transactions list portion of the block. Each receipt contains certain information about the associated transaction, including the state before the transaction execution, the status code of the transaction, the cumulative gas used in the block, the related transaction hash, the contract address where the transaction got executed (nil if there’s no contract), gas used in the transaction execution, hash and number of the block that encapsulated the corresponding transaction, and some other stuff. Since we already have the state tree and transaction tree and that’s sufficient to check the correctness of every transaction execution, why do we additionally need the receipt tree?
Yep… Why? I was wondering, without any reasonable ideas.
Seeking
After Googling for a while, I found someone had the same question on Reddit . And one answer below quoted some words from the Ethereum wiki :

A construction for the Ethereum light clients? Yes, I remembered, when I was reading the Ethereum source code, there often existed several lines of codes left to handle something related to the light client. Maybe the light client is the point of the answer to the question, and perhaps I can find more in the link.
After I had read several posts, it seemed to me that the receipt tree has something to do with the third use of the light client protocol .
I thought I maybe had found the answer, and couldn’t wait to share it with my colleagues.
But on the second day, it turned out that the question wasn’t especially about the receipt tree, it’s nearly about all the three trees and their root hash in the block header… And we had a quite long-time talk about the whole three trees, but didn’t have much progress. Maybe we should search some more canonical explanations or dive into the source code and seek for why.
What’s included in the three trees?
Firstly, we should get clear what’s the stuff included in the three trees.
In Ethereum wiki: Design Rationale , a generalized explanation is given:
Every block header in the Ethereum blockchain contains pointers to three tries: the state trie, representing the entire state after accessing the block, the transaction trie, representing all transactions in the block keyed by index (ie. key 0: the first transaction to execute, key 1: the second transaction, etc), and the receipt tree, representing the “receipts” corresponding to each transaction.
For more details, we can inspect the source code:
The source code of the Account is located at https://github.com/ethereum/go-ethereum/blob/master/core/state/state_object.go#L102 :
|
|
The source code of the Transaction and txdata is located at https://github.com/ethereum/go-ethereum/blob/master/core/types/transaction.go#L38 :
|
|
The source code of the Receipt is located at https://github.com/ethereum/go-ethereum/blob/master/core/types/receipt.go#L50 :
|
|
Every item in these data structures will be analysed if I have time.
What’s the functionality of the three trees?
For now, I sum up something that I think (not really true) is the purpose of the existence of the three trees.
-
State Trees: Store the snapshot of the Ethereum world state and provide fast and convenient service of searching for some information of any account.
- The whole Ethereum Blockchain can be considered as a large state machine, and the state tree in a certain height block is the snapshot of the state machine at that time. As pointed out in State Tree Pruning , with the state tree, new nodes are able to “synchronize” with the blockchain extremely quickly without processing all the transactions from the very beginning. New nodes can download the almost last block from others, verifying the correctness of the block by checking all of the hashed match up with the 3 MP tree roots in the header, and proceed from there, thus joining the Ethereum big family.
- Such a state tree construction also provides much convenience when light clients want to achieve certain information about a account, such as the balance, the nonce, contract code and contract storage of the account at a particular time. They can immediately determine the information by simply asking the network for a particular brunch of the tree down to the node that contains such information, along with a merkle proof (for more about merkle proof, please refer to Merkling in Ethereum ) that can be used to prove the exact node is indeed in the tree.
-
Transaction Trees: Store the transactions in the block and also provide a way to show that certain transaction is in the block.
-
Ethereum is a global singleton state machine, and transactions are what make that state machine “tick,” changing its state. Contracts don’t run on their own. Ethereum doesn’t run autonomously. Everything starts with a transaction. And every block is made up of block header and transaction list (plus the list of uncle block headers in the Ethereum case). So it’s quite reasonable to maintain a transaction tree.
-
Another usage of transaction trees is for light clients to check the existence of a transaction. As Ethereum wiki: Light client protocol reads:
A light client wants to check that a transaction was confirmed. The light client can simply ask the network for the index and block number of that transaction, and recursively download transaction trie nodes to check for availability.
-
-
Receipt Trees: Provide a way to index and search a transaction and enable the light clients to validate blocks.
-
If we look into the Ethereum Yellow Paper , we can see that the yellow paper has already clarified what receipts are made for:

It relates to something about zero-knowledge proof? Not sure about what this is. Seem to like a future feature of Ethereum? But index and search do make sense. As we can see in the receipt data structure above, we have the transaction index in the receipt, so anyone has the receipt can search for the transaction in the blockchain. Meanwhile, through the index, the transactions are in order in the block.
-
However, there’s more about the receipt trees. With the receipt trees, light clients in Ethereum can do something that those in Bitcoin cannot do —— validate a block. In Bitcoin, If an evil miner deliberately give himself more transaction fees, the light clients could not detect this by themselves, what they have is the single block header, without any transactions details. But light clients in Ethereum can be aware of this by some mechanism, as shown in the third use case of the light client protocol :

By maintaining the receipt trees, Ethereum gives more rights to the light clients than Bitcoin.
-
How about the tree roots?
Late in the talk, we found that the receipt contains the transaction hash, so why bother to include the transaction tree root in the block header since we already have all the transaction hash in the receipt tree root?
This question confused me in the talk, but didn’t got answered when the talk ended.
Later, it came out to me that “Tree root != Tree”, the purpose of tree root is to prevent tampering and provide the trusted source of merkle proof. Without the transaction tree root, it’s impossible to check the correctness of the merkle proof of whether a certain transaction is included in the block, for only with the receipt tree root, we can just see a certain receipt is actually in the block, but not the transaction that associated with the receipt! In other words, throught the transaction tree root, light clients can check the existence of the transaction in the block without downloading the list of all transactions.
Summary
The more you think, the more you acquire.
(又一次尝试用我蹩脚的工地英语写点东西)